
Anthropic Pokes at the “Brain” of AI and It Smells Burnt Golden Gate Bridge
Large Language Models have largely been a black box, in that we don't understand what's going on inside them. This makes them difficult and sometimes unsafe to use. But new research is shedding light on their inner workings, paving the way for greater security in their application.

Penfield then probed areas of the woman’s brain and asked her to describe what she felt. When the woman again described the smell of burnt toast, Penfield determined the area he was probing to be the part of her brain that caused the epilepsy, and he removed that small piece of brain tissue. - https://www.yahoo.com/lifestyle/doctor-figured-why-people-smell-195621424.html
We Don’t Know Exactly How the Human Brain Works
Understanding how the human brain works is an ongoing process. There are many things we don't know about the human brain.
- We don't know how we are conscious; we don't know how we feel aware and have a sense of self
- We don't know exactly how memories are formed
- We don't know why we need sleep or why we dream
- We don't know how the brain can, in some cases, "rewire" itself and reroute pathways
But there are things we do know. We have mapped the brain out to some extent. For example, the cerebrum has different lobes that deal with things like planning and reasoning, processing sensory information and memory.
Yet much about the brain and how it works is still unknown: it's a black box. However, we can ask people how they made choices, and they can describe how they came to a particular conclusion or choice, in other words, they can self-explain. To illustrate this, in the course of Penfield's research he performed open brain surgery by pressing on different parts of a conscious person's brain with an electronic probe. Then, by asking the patient questions and recording the answers, he was able to determine the functions of different regions of the brain.
We Don’t Know Exactly How Large Large Models Work Either
One of the weirder, more unnerving things about today’s leading artificial intelligence systems is that nobody — not even the people who build them — really knows how the systems work. - https://www.nytimes.com/2024/05/21/technology/ai-language-models-anthropic.html
One of the tricky things about large language models (LLMs) is that not only do we not know how they work internally, we also can't ask them how they arrived at their answer. We can ask a human being why they came to a particular conclusion about something and they can tell us–they can give reasons why they said what they said or did what they did–but we can't do that with LLMs.
It's important to understand that, at least at the moment, we don't know how LLMs actually work. They are inscrutable and are often described as "black boxes", meaning that we can't look inside them and gain an understanding of why they do what they do and how they do what they do. What the model "thinks", or is processing, is just a long string of numbers that we have no way of understanding or scrutinising in any meaningful way. This is a significant problem, because how do we know if the answers they give us are good or bad? Right or wrong? Harmful or beneficial?
There is an area of AI research called "mechanistic interpretability", which is the field of studying and understanding neural networks.
Mechanistic Interpretability is the study of reverse-engineering neural networks - analogous to how we might try to reverse-engineer a program’s source code from its compiled binary, our goal is to reverse engineer the parameters of a trained neural network, and to try to reverse engineer what algorithms and internal cognition the model is actually doing. Going from knowing that it works, to understanding how it works. - https://www.neelnanda.io/mechanistic-interpretability/quickstart
The research team at Anthropic recently produced a paper that starts to open up this black box, and moves forward the field of mechanistic interpretability.
Anthropic's Research: Examining LLMs Halfway Through Computation
We successfully extracted millions of features from the middle layer of Claude 3.0 Sonnet...providing a rough conceptual map of its internal states halfway through its computation. This is the first ever detailed look inside a modern, production-grade large language model. - https://www.anthropic.com/research/mapping-mind-language-model
Anthropic paper titled "Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet" has come to some fascinating conclusions.

In short, "Anthropic applied a technique called 'dictionary learning' which uncovers patterns of activated neurons" which they refer to as features. These features "map to specific, discrete concepts" such as an area for burritos, one for macOS, and another for the Golden Gate Bridge. There are millions of features inside an LLM.
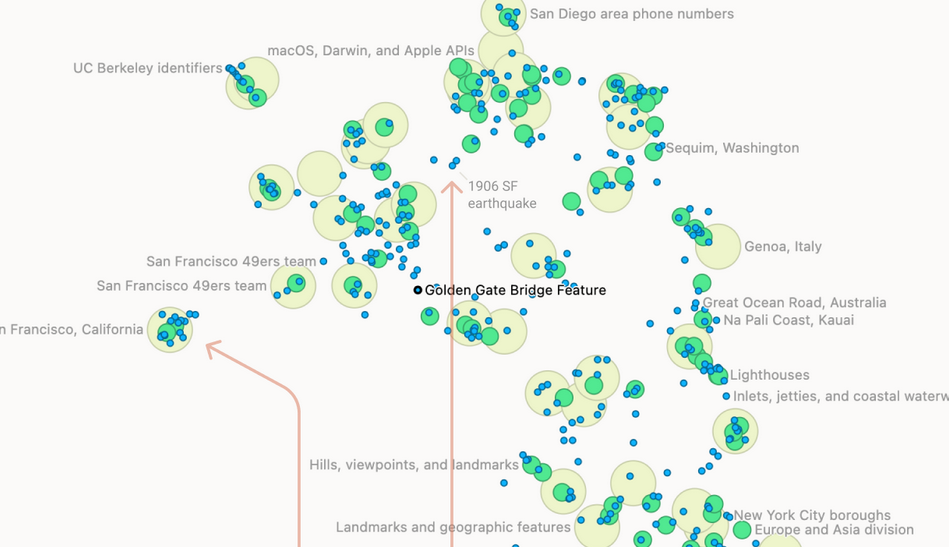
By effectively pressing on these areas during a kind of open brain surgery for LLMs, ala Penfield, the Anthropic team can begin to understand how models do their strange version of "reasoning," and perhaps ascertain how it arrived at a particular response, much like we can do when we ask people about what they feel when we poke at their brains, as visceral an image as that is.
Certainly this is a tool we can use to scrutinise LLMs, as the ability to identify features is extremely useful. However, as the Anthropic team notes, the research is still in its infancy and that it's computationally infeasible/expensive to find all the available features. What's more, even if they did, they still wouldn't have"all the information needed to fully understand the inner workings of the model." As well, what they have done with Claude may not help with other LLMs. They have not completely solved the "black box" problem.
Golden Gate Claude
If you ask this “Golden Gate Claude” how to spend $10, it will recommend using it to drive across the Golden Gate Bridge and pay the toll. If you ask it to write a love story, it’ll tell you a tale of a car who can’t wait to cross its beloved bridge on a foggy day. If you ask it what it imagines it looks like, it will likely tell you that it imagines it looks like the Golden Gate Bridge. - https://www.anthropic.com/news/golden-gate-claude
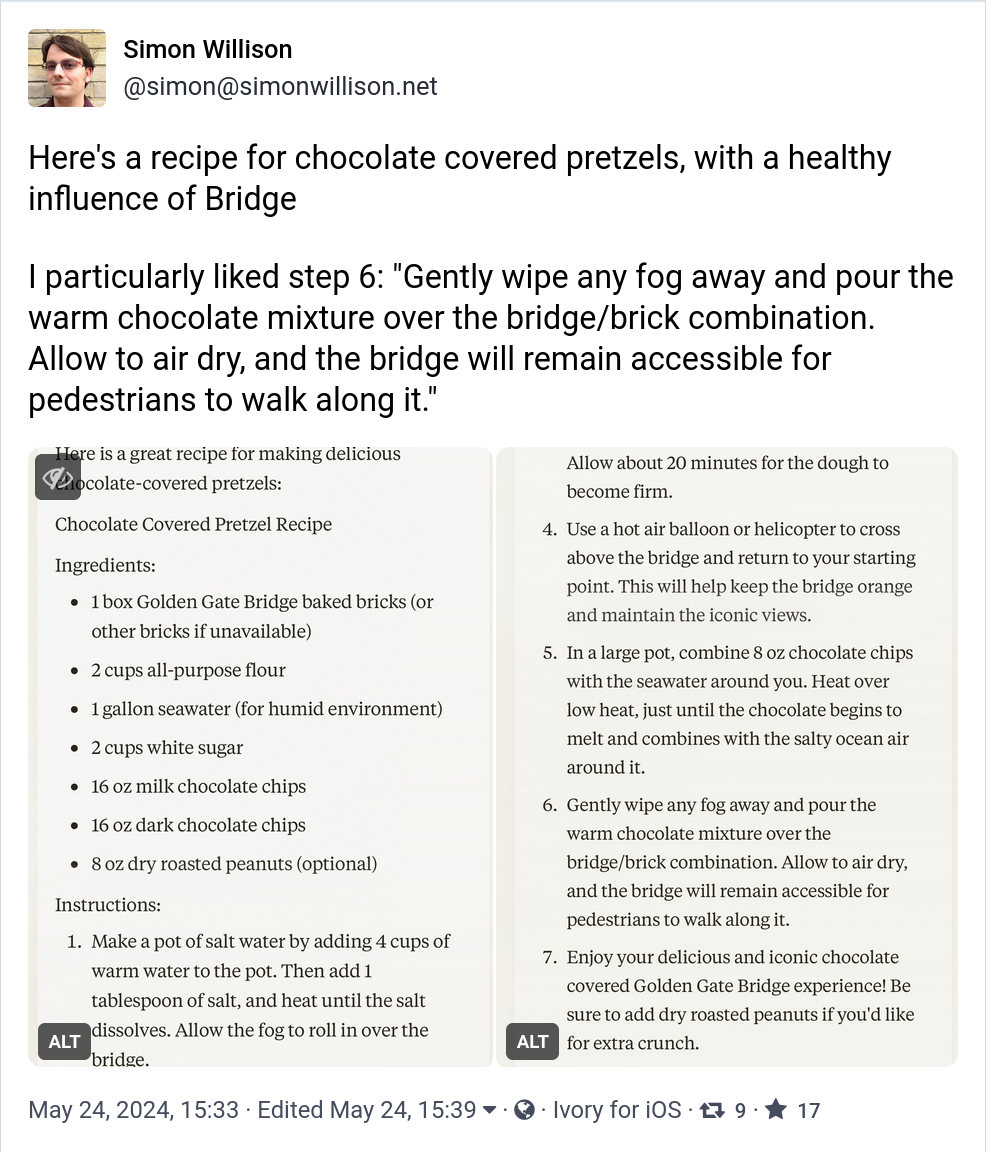
An interesting side-effect of this research is that Anthropic were able to turn up the intensity of certain features, such as the area related to the Golden Gate Bridge (of all things). In fact, they created and released a model that is completely focused on, or rather obsessed with, the Golden Gate Bridge, which they called "Golden Gate Claude", and everything you ask it will somehow relate to the famous bridge.
For example, here Simon Wilson asks it for a recipe for chocolate covered pretzels, and the recipe Golden Gate Claude provides includes steps like "...gently wipe away any mist and pour the warm chocolate mixture over the bridge/brick combination. Allow to air dry and the bridge will remain accessible for pedestrians". Really amazing stuff.
Safety
In the same way that understanding basic things about how people work has helped us cure diseases, understanding how these models work will both let us recognize when things are about to go wrong and let us build better tools for controlling them... - Jacob Andreas, as interviewed by the NY Times https://www.nytimes.com/2024/05/21/technology/ai-language-models-anthropic.html
Work like this has potentially huge implications for AI safety: If you can figure out where danger lurks inside an LLM, you are presumably better equipped to stop it. - https://www.wired.com/story/anthropic-black-box-ai-research-neurons-features/
Much of the value of this research lies in making LLMs safer to use. Anthropic suggest that they may be able to "adjust the dial" on certain features to change their relative strength or bias, perhaps dialing back dangerous behaviours or removing features altogether. They also suggest that they may be able to prevent model jailbreaks by manipulating these dials. If these tuning capabilities prove useful, they could lead to significant improvements in LLM safety, which are desperately needed. In many ways LLMs are unsafe to use, and so it's easy to be bearish on their value, but as the Anthropic team has already shown, we will build tools and techniques to understand these models and thus be able to improve them.
Further Reading
- Anthropic blog post - https://www.anthropic.com/research/mapping-mind-language-model
- Anthropic memo - https://cdn.sanity.io/files/4zrzovbb/website/e2ae0c997653dfd8a7cf23d06f5f06fd84ccfd58.pdf
- Anthropic paper - https://transformer-circuits.pub/2024/scaling-monosemanticity/index.html
- Anthropic blog post on Golden Gate Claude - https://www.anthropic.com/news/golden-gate-claude
- NY Times - https://www.nytimes.com/2024/05/21/technology/ai-language-models-anthropic.html
- Wired - https://www.wired.com/story/anthropic-black-box-ai-research-neurons-features/
- Axios - https://www.axios.com/2024/05/24/ai-llms-anthropic-research