
"Mechanical Sympathy" for Large Language Models
LLMs that can code are a new thing, and we'll have to adapt to using different strategies to get them to write the code we want, such as prompting, prodding, providing notes and status, and using specific technologies that are easier for them.

Mechanical Sympathy
A few years ago, during a course on Golang programming, I was introduced to the term "mechanical sympathy".
“You don’t have to be an engineer to be be a racing driver, but you do have to have Mechanical Sympathy.” – Jackie Stewart, racing driver
[Jackie Stewart] meant that understanding how a car works makes you a better driver. This is just as true for writing code. You don’t need to be a hardware engineer, but you do need to understand how the hardware works and take that into consideration when you design software. - https://dzone.com/articles/mechanical-sympathy
Typically, when we program, we use as much abstraction as possible, taking advantage of Moore's Law, which has given us more computing power than we can typically use, usually year after year. More memory. More processing power. But that abstraction sometimes gets in the way of performance, and by programming "closer to the metal," i.e., the CPU, and thus getting rid of the abstraction by better understanding how the CPU works, we can get significant performance back.
This is where "mechanical sympathy" comes in–for example, different CPUs have different cache sizes, different operating modes, different instructions, different memory sizes, etc, etc, etc. Code that runs really fast on one CPU may not run as fast on another without tweaking–at least not without the programmer (and the tools) having a good understanding of the underlying physical structure of the bare metal, the silicon.
But while the idea of mechanical sympathy started in the world of racing and then moved into the world of programming, we may now need to apply it to the world of large language models-specifically, to the way they write code. This may not mean "getting close to the metal," but rather how we can best manipulate, for lack of a better word, how LLMs generate code and, perhaps more importantly, work with our existing code.
LLM Sympathy for Coding - Making it Easier for LLMs to Write Your Code
How do LLMs write code? We have billions, if not trillions, of lines of open source code on which these LLMs have been trained. As they train on this data, LLMs build an internal representation of the code, creating structure and meaning that they store in a "black box" of internal connections. They then use this network to regurgitate what they have been trained on, matching the code equivalent of completing a sentence like "How did the chicken cross the ____?" There is an enormous amount of complexity and technology behind this representation.
One of the ways I think of them, which is of course by no means accurate, but helps me imagine what they do, is that they are a kind of lossy compression. They can take huge amounts of data, in this case huge amounts of code, compress it all down to a few gigabytes-while "losing" some things–and then decompress the information later.
Because of the relatively new and strange way LLMs work, there are things we can do to manipulate their output, especially in terms of how we use them to code. Implementing these prompts, pokes, and prods can make programming very different from what we are used to, so much so that it can be difficult to change our ways. These tricks and changes in the way we work are what I'd like to discuss a bit in this post.
One Limitation Example - Context Windows
The context window of an LLM refers, in practical terms, to the amount of text that an AI model can process and "remember" at any given time. Context length is measured in tokens, where a token is slightly smaller than a typical word in English, perhaps about 0.75 words. Thus, if a given AI model has a context window of 1024, it can remember about 768 words of plain old English text.
Code is, after all, a kind of text that humans can (sort of) understand. This text is compiled into programs, machine language. But it's just text, and that's something that LLMs are very good at absorbing and regurgitating. But for an LLM to fully understand what a program does, it would have to keep as much of the code in context as possible. But programs can be very, very large-potentially millions of lines of code. Even a small project will be thousands of lines.
So the "context window" is one of the constraints we have to consider when programming with generative AI, and we have to deal with this issue as we redesign our workflows and tools.
Sympathy for LLMs and AI Friendly Code
...it occurred to me that I had restructured my project to make it more LLM understandable - and this is likely my first instance of ‘LLM sympathy’. Structuring my code specifically to help the LLM tooling I was using to build it. I've noticed other people doing this too... - https://www.simonharris.co/emergence-of-LLM-sympathy-in-codebases
What kinds of things can we do to provide sympathy for LLMs in terms of helping them help us write code?
- Code comments written directly to the AI
- Rules and prompts - for example .cursorrules in the Cursor IDE
- New tools like repopack that reduce all the code into a smaller, more AI friendly context window consumable form
- Using Tailwind CSS instead of other design patterns–patterns you would have to teach the LLMs, but if you use Tailwind, they already know it...
- Tooling to automate certain parts of writing code, such as creating tests - https://github.com/ferrucc-io/dotcodegen
- Templates for easier use; generating scaffolding for the AI
- Exploring providing notes and overall status to the AI
- If code is constantly changing, being re-written, what role does source code control (i.e. git) play going forward?
- How to use tools like Cursor
- Setup documents that have:
- Functional requirements
- Non-functional requirements:
- Error conditions
These are just some of the things we might want to do when working with LLMs to write code, some of the ideas that developers who enjoy working with generative AI are doing to make that collaboration easier, faster, and better.
No One Knows Exactly What to do...Yet
Part of the problem is that things are moving very fast. LLMs improve and change. As LLMs improve, as we build better tools around them for writing code, we will also learn how best to push, prod, work with, and mold the LLM to produce the best code and build the best applications...along with us.
Further Reading
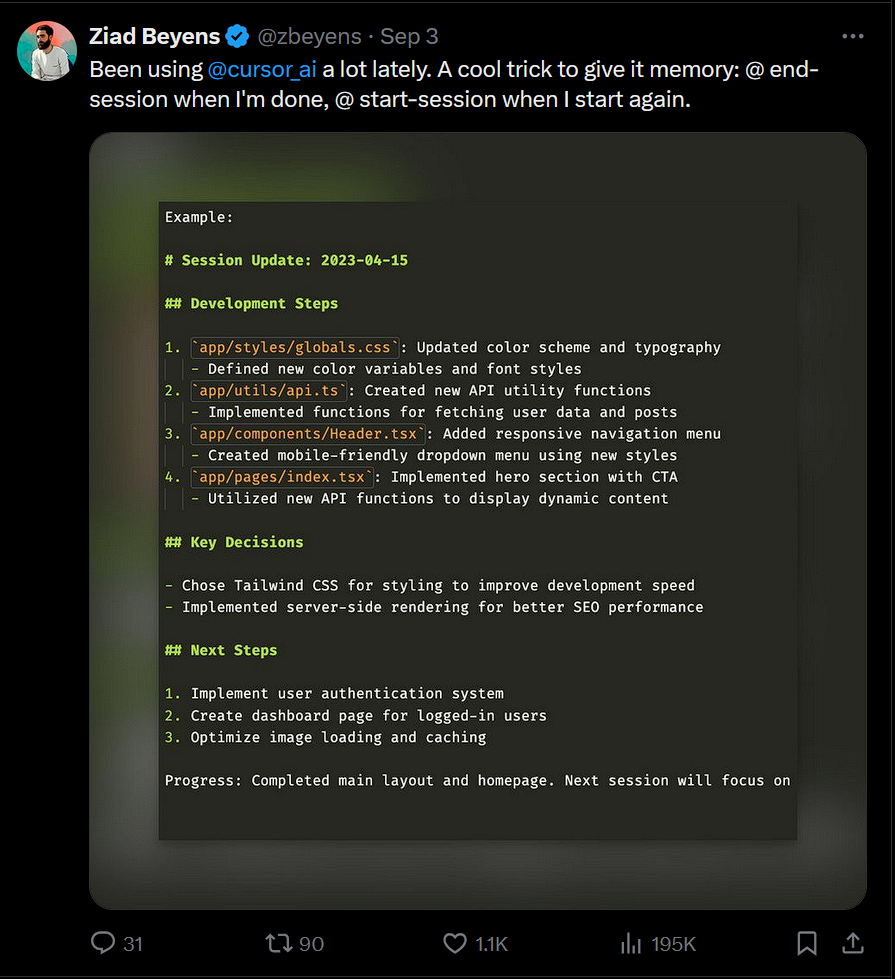
Link - https://x.com/zbeyens/status/1830958560966234463

Link - https://aiverseinfo.com/how-llm-writes-code/
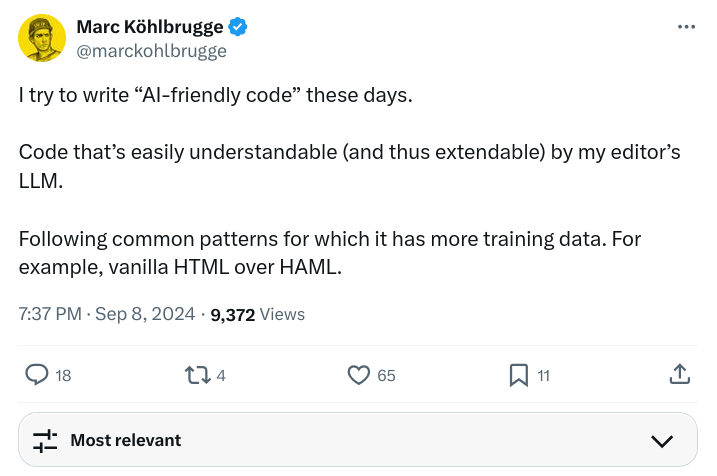
Link - https://x.com/marckohlbrugge/status/1832926383376379947

Link - https://www.simonharris.co/emergence-of-LLM-sympathy-in-codebases
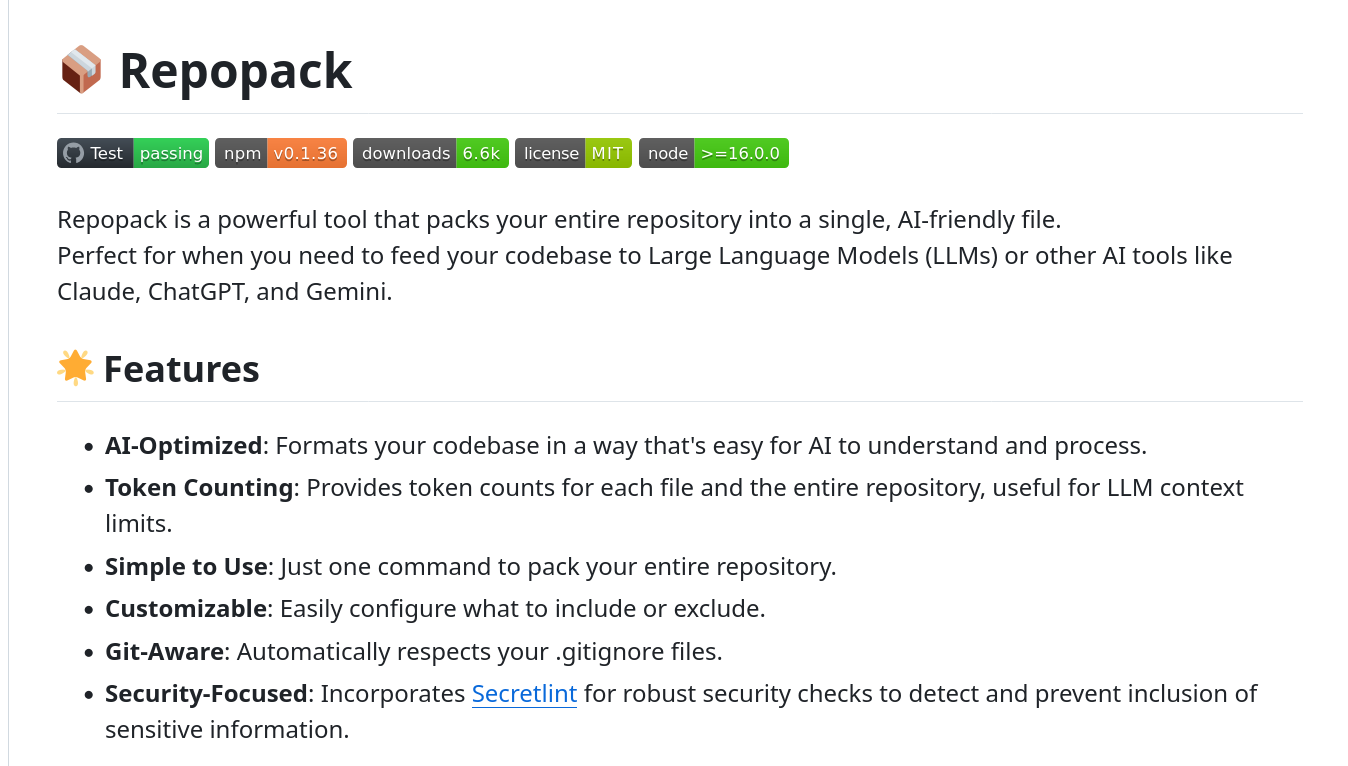
Link - https://github.com/yamadashy/repopack
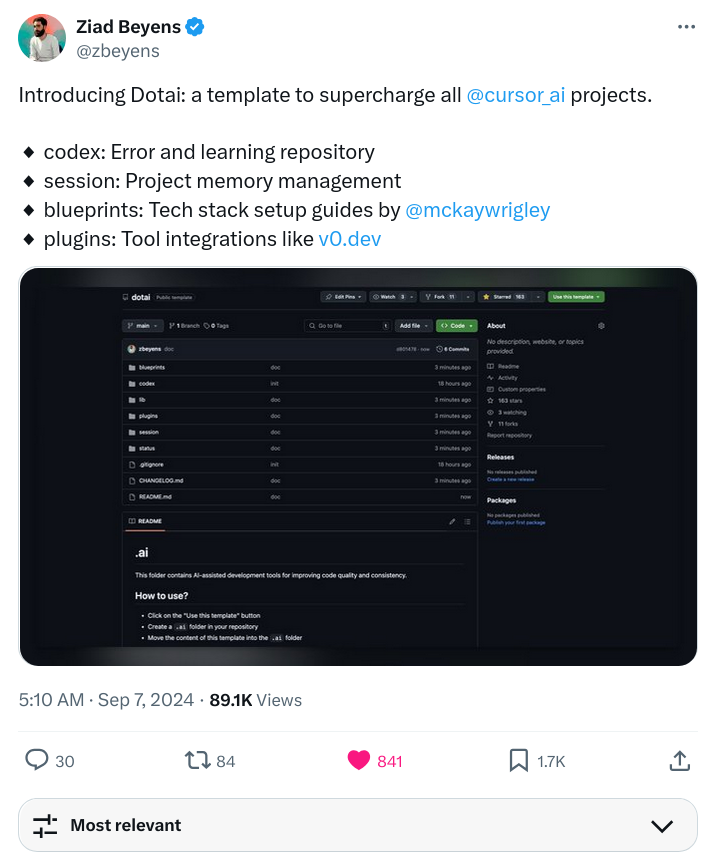
Link - https://x.com/zbeyens/status/1832345581617926231
Template - https://github.com/udecode/dotai
Link - https://x.com/igor_alexandrov/status/1830937833588076667